Blue Yonder’s python library tsfresh automatically extracts features from time series or sequences and it has just been released as an open source project.
Time series: They’re everywhere
The computerization and automation of manufacturing operations as part of Industry 4.0 trend promises to improve existing value chains and yields new business models in the industrial sector. The research project iPRODICT is one of such initiatives. It partly automates business processes related to the continuous casting of steel billets at the German steel manufacturer Saarstahl. Both iPRODICT and Industry 4.0 rely on machine learning techniques to make industrial operations smart. Statistical models need to incorporate changing states of processes and objects, recorded as time series or sequences of values. As sensors and storage options become more affordable, the amount of temporally annotated data is ever increasing. Aside from these research endeavours, Blue Yonder is an expert for the application of machine learning in retail scenarios. In the retail field, one also has to constantly inspect time series such as weather data, competitive prices or sales. Sales typically have different dynamics depending on the product category, for example: Sales of Gingerbread and mulled wine will both peak during the winter months, while bottled water will have more continuous sales.
Two approaches to dealing with structured input
There are two ways on how to deal with structured input such as images, time series or videos for classification, regression, clustering, forecasting and related machine learning tasks. Either the machine learning algorithm:
- incorporates such input directly
- maps it to another, possibly lower dimensional, representation
What does that mean for our time series data? A data scientist has two options when building models on time series data:
- Dedicated time series model: Here, the machine learning algorithm incorporates the time series directly. This model behaves like a black box and it can be hard to explain its behavior. Examples include autoregressive models or k-nearest neighbors classifiers under the dynamic time warping distance.
- Feature based approach: Here, the time series are mapped to another representation, possibly in a lower dimensional space. The mapping is conducted by a feature extraction algorithm that calculates characteristics like the average or maximal value of the time series. The features are then passed as a feature matrix to a ”standard” machine learning algorithm such as a neural network, random forest or support vector machine. This approach has the advantage of a better explainability of the results. It also enables us to use the well-developed theory of supervised machine learning.
As the no free lunch theorem states, there is no such thing as a ”best approach”. However, from a business-specific point of view, a feature-based approach is preferred due to their better explainability. Blue Yonder clients often want to know why an algorithm or a whole Machine Learning pipeline decides the way it does. It’s not always possible to explain the algorithm’s decisions with dedicated time series models. With a feature-based approach, the data scientist has better control over what the algorithm is actually learning.
Automatic extraction of hundreds of features
Data scientists often spend most of their time either cleaning data or building features. While we can’t change the first, the second can be automated. The python package tsfresh automatically extracts hundreds of features from time series. It relieves the data scientist from building features and can extract them automatically. You will have more time to study the newest deep learning paper, read hacker news or build better models. The calculated features describe the basic characteristics of the time series, including the number of peaks, the average or maximal value, or even more complex features such as the time reversal symmetry statistic. For example: 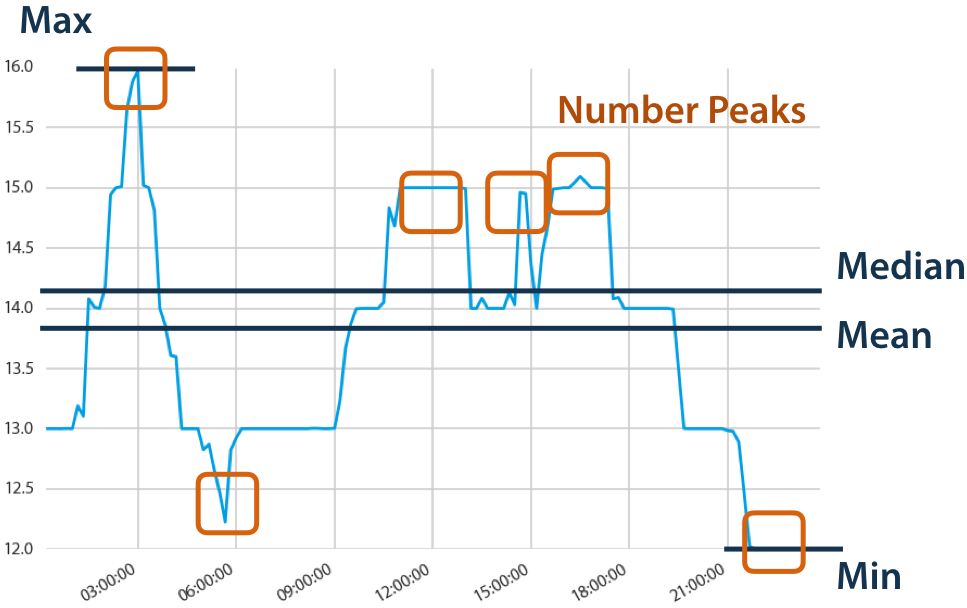 Here, tsfresh calculated the mean, median, maximum and minimum values of the inspected time series. It also counted the number of local peaks of the time series. Now, you may be wondering, what could the other 95+ features be? To satisfy your curiosity, you can find them in the tsfesh documentation.
Here, tsfresh calculated the mean, median, maximum and minimum values of the inspected time series. It also counted the number of local peaks of the time series. Now, you may be wondering, what could the other 95+ features be? To satisfy your curiosity, you can find them in the tsfesh documentation.
Forget irrelevant features
Time series often contain noise, redundancies or irrelevant information. As a result, most of the extracted features are not useful for the machine learning task at hand. To avoid extracting these irrelevant features, the tsfresh package has a built-in filtering procedure that evaluates the explaining power and significance of each characteristic for the regression or classification tasks at hand. It is based on the well-developed theory of hypothesis testing and uses a multiple test procedure. The filtering procedure that we’ve developed will control the percentage of irrelevant features among all the extracted features for any distribution and dependency structure asymptotically. You can find the algorithm in all details in the following paper: Maximilian Christ , Andreas W. Kempa-Liehr and Michael Feindt (2016). Distributed and parallel time series feature extraction for industrial big data applications. ArXiv e-print 1610.07717, https://arxiv.org/abs/1610.07717.
Fresh, scientific and free
Written in Python and shared under the MIT license, tsfresh is a new open source package that automates time series feature extraction based on Pandas dataframes. It’s also based on scientific papers. So it is fresh, scientific and free. Next steps: Interested in giving tsfresh a try? You can find information and the source of tsfresh here:
- Repository
- Gitter Chat
- Documentation tsfresh is under active development. Help us shape its future by telling us what you would like to see next on GitHub. We always appreciate any feedback or contributions!