
Coiled Webinar “Science Thursday”: Data Processing at Blue Yonder - One Supply Chain at a Time
This is a guest article by Christiana Cromer and first appeared on the Coiled blog. It is a write-up of the Coiled “Science Thursday” session with Florian Jetter from Blue Yonder. Coiled is the company founded by Matthew Rocklin, creator and maintainer of Dask
Recently, Coiled’s Head of Marketing and Evangelism Hugo Bowne-Anderson and Software Engineer James Bourbeau were joined by Florian Jetter, Senior Data Scientist at Blue Yonder, for a Science Thursday on “Data Processing at Blue Yonder: One Supply Chain at a Time”. Blue Yonder provides software-as-a-service products around supply chain management.
In supply chain management, billions of decisions must be made surrounding how much to order, when to ship products, how much stock to keep in distribution centers, and so on. Blue Yonder automates and optimizes the decision making processes of supply chains with machine learning and scaled data science. They heavily leverage Python and Dask for processing data-intensive workloads, and a significant part of Florian’s job surrounds maintaining Dask for Blue Yonder.
You can catch the live stream replay on our YouTube channel by clicking below.
Thanks to Florian’s comprehensive demo, after reading this post, you’ll know:
- That buying milk at your local supermarket is a highly non-trivial process,
- How to incorporate a relational database into your data pipeline,
- How to build a ML data pipeline at terabyte scale using Parquet, Dask, and Kartothek,
- How to join data at scale without breaking a sweat (kind of),
- Where to go next with resources on Dask, supply chains, and more.
Thank you to Florian and his colleague Sebastian Neubauer, Senior Data Scientist at Blue Yonder, who also joined us for this live stream, for the feedback on an earlier draft of this article!
Blue Yonder’s approach to the problem of supply chain management
“We need to crunch this together, ideally in a way that is cheap to store and in a way that data scientists can scale-out, and this is where Dask comes in.”
First things first, we were curious to know how many clusters Blue Yonder uses. Florian said, “We have a lot of customers and different environments, this all totals to around 700 clusters at the moment.” 200 of those clusters are production use cases, which means they’re fully automated with no human involvement.
Before we jumped into the demonstration, Florian gave us a lesson on supply chain networks, outlined through the example of a grocery store buying milk. When thinking about supply chain fulfillment, two questions emerge:
1) The prediction: What is the demand? (which turns out to be a huge machine learning problem), and
2) The decision: What’s the optimal amount we should order, considering the current state of the supply chain?
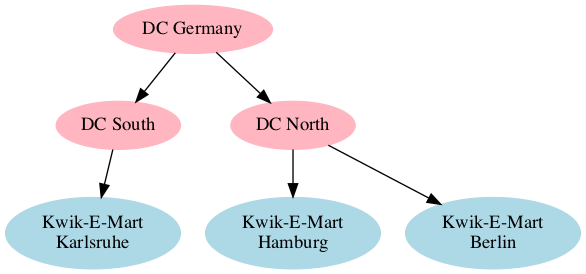
Blue Yonder approaches the concept of supply chain management by breaking it down into pieces. A relatively simple example could be: store level demand forecast (ML), store/distribution center network optimization, vendor ordering, and truckload, as seen in the graph below.

This an ongoing and iterating process. Florian noted that “the number of feedback loops involved makes this a highly non-trivial problem”. So, your glass of milk is more complicated than it looks!
We then jumped into a demonstration in which Florian walked us through an example of building out a ML data pipeline for a mid-sized vendor. We saw how quickly this involves 10 million time series. You can follow along with this notebook.
As an example, using 10 years of data from the customer, Blue Yonder has to process 40 terabytes of uncompressed data, which represents a huge data engineering challenge.
“We need to crunch this together, ideally in a way that is cheap to store and in a way that data scientists can scale-out, and this is where Dask comes in.”
Everything after the initial data ingestion, which is a web service, is then exclusively powered by Dask. Optimizing each customer’s specific network for things like strategy and regional events creates another layer of complexity and data processing.
James asked a great question about how COVID-19 impacted the machine learning models and engineers at Blue Yonder. “When COVID hit us it was a big deal because our customers were hugely affected and I must admit our machine learning models couldn’t easily cope with this drastic of a change on demand and supply.” In response to the pandemic, Florian explained how Blue Yonder created a task force to look at the way the machine learning models were impacted and build out different models that could better withstand the ongoing turbulent conditions. Furthermore, due to the high level of automation and standardization in the whole process, the changes could be applied to the customers much faster than it would be possible without machine learning.
Scaling Supply Chain Decisions with Dask: Path to an Augmented Dataset
“The first problem we want to solve is how do we get this data out of the database and into a format where we can actually work with it.”
To get giant amounts of customer data into Dask, Florian outlines five key ingredients for success:
- Connection
- SQL / Query
- Schema (Depends on 2.)
- Partitions
- Avoid killing your database
For a fast connection, Blue Yonder uses turbodbc, which you can learn more about here. When it comes to the SQL Query, you of course need to write your query in a way that you can download subsets of data. Blue Yonder does this by slicing by time dimension and by a partition ID. Finding the right partition ID and splitting your data up into smaller, more manageable pieces is essentially the pre-processing groundwork before Dask can take over.
Florian then dove into showing us how Dask comes in and scales out the process. James put on his Dask maintainer hat to thank the Blue Yonder team for contributing, owning, and maintaining the semaphore implementation. Florian noted that though it looks easy, this process was imperative to avoiding bottlenecks and deadlocks with their customer data.
“This whole thing needed to be resilient. What I’m showing is a simple problem but in the background, it’s of course incredibly complex”
ML data pipeline at terabyte scale
Florian then showed us how to build out a ML data pipeline at terabyte scale using Parquet, Dask, and Kartothek.
“We want to persist intermediate data as a parquet file using Kartothek to create resilience, consistency (e.g. data may change an hour later), and for data lineage purposes.”
Kartothek is an open-source library that is essentially a storage layer for parquet data created by Blue yonder. Florian noted:
“If you have huge parquet data sets and you need more control over how they are produced and managed and additional metadata information, this is where Kartothek comes into play.”
He also explained the implementation of a partition encoding key for compatibility purposes.
Where exactly is the ML? Using Dask, Florian was able to apply a machine learning model to each partition of his dataset. This lets Blue Yonder’s machine learning experts make complex predictions. Florian said:
”Once we have these predictions it’s also just a Dask dataframe. I’ll store them again as a Kartothek data set and I can build other indices on my predictions…and then data scientists can browse these prediction tables however they want”.
Resources
A huge thank you to Florian Jetter for leading us through this fantastic session and to the entire team at Blue Yonder! We covered a lot of ground during this live stream and in this blog. Here are some resources for further learning: