
What is “Data Science”?
There are many definitions of what data science is though some are not really serious:
“Data science is statistics on a Mac. ” @bigdataborat
Or this one, which is surprisingly to the point:
“Data scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.” @josh_wills
However, for this blog post, I want to use my own definition:
“Data science aims to build systems that support and automate data-driven operational decisions.” @sebineubauer
According to this rather restrictive definition, the only purpose of data science is to support and automate decisions, which might come as a surprise for some people. What are these “operational decisions” we are talking about? These are decisions that businesses need to make in huge numbers, on a frequent and regular basis, that have a direct impact on the business KPI’s and the outcome can be evaluated in short time scales. Examples might be “What is the best price for each single product tomorrow?” or “What is the optimal amount for each single product for the next order sent to supplier X?”.
As people are frequently influenced in ways they can’t even know (see this long list of approved human decision biases ), these automated decisions can out-perform human operational decisions in most cases. Therefore they can significantly improve the efficiency of business processes. But all that really means is that data science brings to operational decision making what industrial robots bring to manufacturing. Just as robots automate repetitive, manual manufacturing tasks, data science can automate repetitive operational decisions.
What is DevOps?
Briefly, the DevOps movement tries to overcome a widespread problem: Developer teams are eager to develop new features that go live as early as possible. At the same time, operations teams are responsible for system stability and will block new features as long as possible as all changes come with risk. In this conflict both teams loose sight of the common objective of delivering value to the customer with highly-stable new features. For a more detailed explanation, I recommend this article.
Troublemaker “Data Science”
A fictitious, but nonetheless realistic conversation between two managers at a conference goes like this: “Are you already doing this data science stuff?”, “We have a team of data scientists in place for about a year now, but the progress is very slow” To better understand, where this “very slow” progress comes from in many data science efforts, we need to have a look at a typical data science workflow for automating business decisions. This example workflow is focused on the retail sector but also holds for other industries with only minor modifications.
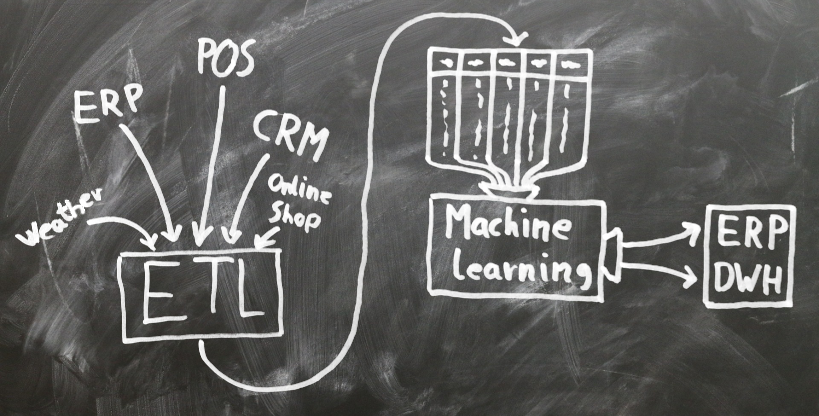
- Pull all kinds of necessary data from a variety of sources: * Internal data sources like ERP, CRM, POS systems, or data from the online shop * External data, like weather, public holidays
- Extract, transform, and load the data: * Relate and join the data sources * Aggregate and transform the data * In the end, everything ends up in “one big table”
- Machine learning and decision-making: * Use historic data to train the machine learning model * For decision-making, current, up-to-date data is used
- The resulting decisions are loaded, either back into the ERP system or some other data warehouse
With those steps, touching essentially all parts of the business, it becomes apparent that it needs to be deeply integrated into the business processes in order to be effective as a decision making system. This is by far the biggest source for the troubles created by data science efforts. In order to successfully integrate data science, one needs to transform and modify the core business processes, which is a difficult task.
Data science is greedy by nature
“The current database should be sufficiently sized for the next year” - No data scientist ever! It’s commonly assumed that the data scientists are greedy because they seem to have an unrealistic understanding of the available resources. But really, it’s data science itself that is greedy by nature. In general, the outcome of a data science effort gets better with:
- More features (“columns”)
- More historic data (“rows”)
- More independent data sources (e.g. weather, financial markets, social media…)
- More complex algorithms (e.g. deep learning)
See? It isn’t the data scientists’ fault! They are, in principle, right to make their requests. Luckily, there are ways to overcome this problem as we will see later on.
Another issue is underestimating the sheer number of decisions. Consider daily demand forecasts for a rather small supermarket chain with 100 stores and 5000 products. We would need 14 days of daily forecasts to be of any use for the replenishment algorithm. But what that really means is that 7 million forecasts need to be calculated, processed and stored every day.
Furthermore, because many different data sources are needed for an effective machine learning model, new coherence and entanglement may be introduced between departments. The whole organization must come together to agree on common identifiers and data types. Formerly disconnected subdivisions need to synchronize their complete data flow. For example, an automated daily replenishment system might depend on promotions data from the marketing department and the stocks data from all stores. All the necessary data, from marketing and all stores needs to be available at fixed time of the day in order to be able to calculate the decisions and send them to the suppliers in time. This entanglement is a big problem and can lead to serious political and emotional tensions in the company.
Data scientists versus the rest of the company?
Now back to DevOps. This movement tries to overcome this potential misalignment of developers and operations teams. This problem will inevitably happen if you try to build the automated decision system with a data scientist team in a separated silo. Because of the entangled and greedy nature of data science, this team will have a very hard time getting this system successfully integrated “against” the other teams operating with different incentives.
To prevent or fix those kinds of problems, the fundamental principles of the DevOps mindset also apply here:
- Align the objectives of all teams so that they are not working “against” each other, but all working together towards a common goal
- Tear down the walls between silos and build cross functional teams
- Measure the improvements and allocate resources and features based on the measured added value for the customer
It is about commitment
Decision-making is at the heart of a company’s success. So when introducing data science, the entire company, throughout all hierarchies and divisions needs to accept and appreciate that automated decision making using data science is a serious part of the company’s value stream. This most likely means that you need to change established processes, reorganize teams and the company’s structure. To succeed with these changes, you need the necessary buy-in: Everyone needs to understand why the change is happening and back the decision. Without this wholehearted commitment, automated decision making has no chance for successful integration.
In turn, the data science effort has to strongly focus on the true added value: One needs to evaluate the costs of the implementation (including costs of technical debt, increased complexity, increased entanglement, etc) and compare it with the projected gain due to the improvements. Data science is never a self purpose.
Tear down data science silos
One of the key goals of DevOps is aligning team efforts towards common company objectives and the tearing down of walls between siloed teams. Putting data scientists together into a separate team in a separated room is a sure path to a failing data science effort.
Instead, embed the data scientists in a cross functional team. This builds the whole decision-making system end-to-end and will take care to align this effort with the company goals. Once every department is aligned, the data scientists will not be working against the other departments. Instead, the success of the decision-making system becomes a shared common interest. Global optimization by the joint efforts towards a common goal replaces local optimization towards self-centered and unaligned goals.
This cross functional team commits to the same quality standards as all other teams. There is no room for any compromise on quality, resilience or robustness. On the contrary, because of the high risk attached to automated decision-making, even higher standards should be applied. At the same time, following the “lean thinking” methodology, create an environment where it is simultaneously cheap and safe to make experiments.
Fighting greediness with Ockham’s razor
There is a problem-solving principle called “Ockham’s razor” which says: “Among competing hypotheses, the one with the fewest assumptions should be selected.”. Translated into the data science domain, we can reformulate this principle to:
“If the outcomes of two data science models are compatible, take the one with smaller resource footprint.” @sebineubauer
This simple rule gives a clear instruction on how to build data science models, so that the problem of the inherent greediness of data science is solved. Without measuring the generated value and applying this principle throughout the whole implementation cycle, you will likely face exploding costs with limited returned value. Make sure the data scientists are committed to this important principle, because admittedly, it is very hard to work against data scientists. They have the data and the expertise to come up with arguments that are hard to make an objection to. Create a culture of efficiency that is as simple as possible, but as complex as needed.
The same holds for the use of different data sources. In the domain of data security, there is the “need to know” principle, which states data should only be accessible to people who need to have access. Applied to data science, it means that we measure the value of adding more data sources, but rigorously purge them again if the improvement is not significant enough to justify the additional data dependency.
Summary
Data science is about supporting and automating decision-making and is becoming ever more important for most companies. Because of the role as a decision making system, data science has to be in the core of the business processes. This fact brings a whole bunch of serious problems and some of them, especially those of cultural nature can be catastrophic. Half-hearted attempts lead to a waste of time and money – at best – and nourish data science’s reputation as a troublemaker.
Properly integrated data science, however, is a game changer you cannot afford to ignore. Embrace data science with a DevOps mindset. Measure important KPIs, learn from experiments, and improve your processes accordingly over and over again. This is the path to becoming a truly data-driven company.